Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server unter Linux
SQL Server unter Linux
In diesem Artikel werden Speicherkonfigurationen für SQL Server für Linux behandelt, einschließlich mssql-conf Speicherbeschränkungen, Steuerelementgruppeneinstellungen (cgroup), Docker-Containerspeicherbeispiele und Überlegungen zum Austausch von Speicherplatz.
Note
Empfehlungen zu Speicher, Kernel, CPU und Netzwerk finden Sie unter bewährte Methoden zur Leistung: Speicher, Kernel, CPU und Netzwerk für SQL Server für Linux.
Festlegen eines Speicherlimits mithilfe von mssql-conf
Um sicherzustellen, dass genügend freier physischer Arbeitsspeicher für das Linux-Betriebssystem vorhanden ist, verwendet der SQL Server-Prozess standardmäßig nur 80 Prozent des physischen RAM. Bei einigen Systemen mit großen Mengen physischem RAM kann es sich bei 20 Prozent um eine signifikante Zahl handeln. Bei einem System mit 1 TB RAM lässt die Standardeinstellung beispielsweise rund 200 GB RAM ungenutzt. In diesem Fall sollten Sie das Arbeitsspeicherlimit auf einen höheren Wert festlegen.
Sie können diesen Wert mithilfe des mssql-conf Tools oder der MSSQL_MEMORY_LIMIT_MB Umgebungsvariablen anpassen. Weitere Informationen finden Sie in der Einstellung "memory.memorylimitmb ", die den für SQL Server sichtbaren Speicher steuert (in Einheiten von MB). Ausführliche Anleitungen zur Größenanpassung finden Sie unter Richtlinien zum Festlegen von Speichergrenzwerten für Linux und in Containern.
Unterstützung von cgroup v2
SQL Server erkennt und berücksichtigt Kontrollgruppeneinschränkungen (cgroup) v2, beginnend mit SQL Server 2025 (17.x) und SQL Server 2022 (16.x) Kumulatives Update (CU) 20. Diese Einschränkungen bieten eine differenzierte Kontrolle im Linux-Kernel über CPU- und Speicherressourcen und verbessern die Ressourcenisolation in Docker-, Kubernetes- und OpenShift-Umgebungen.
In früheren Versionen können containerisierte Bereitstellungen auf Kubernetes-Clustern (z. B. Azure Kubernetes Service v1.25+) fehler im Arbeitsspeicher (OOM) auftreten, da SQL Server in Containerspezifikationen definierte Speichergrenzwerte nicht erzwungen haben. Die Unterstützung für cgroup v2 behebt dieses Problem.
Cgroup-Version überprüfen
stat -fc %T /sys/fs/cgroup
Die Ergebnisse sind wie folgt:
| Result | Description |
|---|---|
cgroup2fs |
Sie verwenden cgroup v2 |
cgroup |
Sie verwenden cgroup v1 |
Wechseln zu cgroup v2
Der einfachste Weg ist die Auswahl einer Distribution, die cgroup v2 von Haus aus unterstützt.
Wenn Sie manuell wechseln müssen, fügen Sie der GRUB-Konfiguration den folgenden Parameter hinzu:
systemd.unified_cgroup_hierarchy=1
Aktualisieren Sie dann GRUB. Führen Sie beispielsweise unter Ubuntu Folgendes aus:
sudo update-grub
Führen Sie auf Red Hat Enterprise Linux (RHEL) Folgendes aus:
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
CPU-Grenzwertberichterstattung mit cgroup v2
Wenn Sie CPU-Grenzwerte mit cgroup v2 konfigurieren, zeigt SQL Server nicht die konfigurierte CPU-Kernanzahl im Fehlerprotokoll an. Stattdessen wird weiterhin die Gesamtanzahl der Host-CPUs angezeigt.
Wenden Sie die folgende Konfiguration an, um SQL Server Zeitplan- und Abfragepläne (z. B. Parallelitätsentscheidungen) mit der beabsichtigten CPU-Anzahl auszurichten, die in cgroup v2 definiert ist.
Konfigurieren der Prozessoraffinität
Legen Sie explizit SQL Server Prozessoraffinität so fest, dass sie dem Cgroup-Ausführungskontingent entspricht. Im folgenden Beispiel ist das cgroup-Kontingent vier CPUs auf einem achtkernigen Host:
ALTER SERVER CONFIGURATION
SET PROCESS AFFINITY CPU = 0 TO 3;
Diese Konfiguration stellt sicher, dass SQL Server Scheduler nur für die beabsichtigte Anzahl von CPUs erstellt. Weitere Informationen finden Sie unter ALTER SERVER CONFIGURATION und Verwenden Sie PROCESS AFFINITY für Node und/oder CPUs.
Traceflag 8002 aktivieren (empfohlen)
Aktivieren Sie die Ablaufverfolgungskennzeichnung 8002, um weiche Affinität auf der SQLPAL-Ebene zu verwenden:
sudo /opt/mssql/bin/mssql-conf traceflag 8002 on
Standardmäßig sind Scheduler an bestimmte CPUs gebunden, die in der Affinitätsmaske definiert sind. Das Trace-Flag 8002 ermöglicht es Schedulern stattdessen, zwischen CPUs zu wechseln, wodurch die Leistung im Allgemeinen verbessert wird, während die Affinität und cgroup-Einschränkungen eingehalten werden. Weitere Informationen finden Sie unter DBCC TRACEON – Ablaufverfolgungsflags.
Starten Sie SQL Server neu, nachdem Sie das Ablaufverfolgungskennzeichen aktiviert haben.
Erwartetes Verhalten
Nach dem Neustart:
SQL Server erstellt nur die Anzahl der Planer, die durch die Affinitätseinstellung definiert sind (z. B. vier Planer).
Der Linux-Kernel erzwingt weiterhin das Cgroup v2 CPU-Ausführungskontingent.
Abfrageoptimierungs- und Parallelitätsentscheidungen basieren auf der vorgesehenen CPU-Anzahl und nicht auf den Gesamthost-CPUs.
Note
Das SQL Server Fehlerprotokoll zeigt möglicherweise weiterhin die Gesamtanzahl der Host-CPU an. Dieses Protokollierungs- und Anzeigeverhalten wirkt sich nicht auf die tatsächliche CPU-Auslastung, die Erstellung des Zeitplans oder die CPU-Erzwingung durch cgroup v2 oder Prozessoraffinität aus.
Weitere Informationen finden Sie in den folgenden Ressourcen:
- Schnellstart: Bereitstellen eines Linux-SQL-Server-Containers in Kubernetes mithilfe von Helm-Charts
- Control Group v2 (Linux Kernel-Dokumentation)
Richtlinien zum Festlegen von Speicherbeschränkungen für Linux und in Containern
SQL Server für Linux verfügt über mehrere Speichersteuerelemente, die auf unterschiedlichen Ebenen ausgeführt werden. Die folgende Tabelle und das folgende Diagramm zeigen, wie jede Ebene den verfügbaren Arbeitsspeicher von Host-RAM auf den Pufferpool einschränkt.
| Grad | Festgelegt durch | Description |
|---|---|---|
| Host | Hardware-/VM-Konfiguration | Physischer RAM auf dem Server oder virtuellen Computer (VM). |
cgroup-Grenzwert (docker run --memory, systemd, oder manuell) |
Containerlaufzeit, systemd Segment oder manuelle cgroup Konfiguration |
Vom Kernel erzwungene Obergrenze (memory.max) für alle Prozesse innerhalb von cgroup. Optional unter Bare-Metal-Linux. |
SQL Server Prozess (memorylimitmb / MSSQL_MEMORY_LIMIT_MB) |
mssql-conf oder Umgebungsvariable |
Gesamtspeicher für alle SQL Server Komponenten. Muss unter dem Grenzwert cgroup (sofern vorhanden) oder dem Hostspeicher liegen. |
Pufferpool (max_server_memory) |
sp_configure |
Der Cache von 8-KB-Datenseiten. Muss niedriger sein als memorylimitmb. |
| Headroom | Berechnet (Abstand zwischen Grenzwerten) | Die Differenz zwischen dem Grenzwert cgroup (oder dem Hostspeicher) und memorylimitmb, die für Betriebssystem-Overhead und Hilfsprozesse vorbehalten ist. |
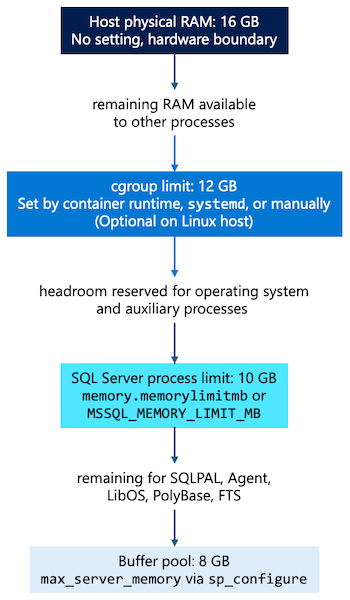
Beachten Sie beim Festlegen von Speichergrenzwerten für SQL Server unter Linux die folgenden Richtlinien:
Verwenden Sie
cgroupin Containerbereitstellungen, um den für den Container verfügbaren Gesamtspeicher zu begrenzen. Diese Einstellung richtet die obere Grenze für alle Prozesse innerhalb des Containers ein.Die Speichergrenze (ob festgelegt durch
memorylimitmboder dieMSSQL_MEMORY_LIMIT_MBUmgebungsvariable) steuert den Gesamtspeicher, den SQL Server unter Linux über alle komponenten hinweg zuordnen kann, z. B. pufferpool, SQLPAL, SQL Server-Agent, LibOS, PolyBase, Full-Text Search und alle anderen prozesse, die in SQL Server unter Linux geladen wurden.Die
MSSQL_MEMORY_LIMIT_MBUmgebungsvariable hat Vorrang vormemorylimitmbder Definition inmssql.conf.memorylimitmbkann den tatsächlichen physischen Speicher des Hostsystems nicht überschreiten.Legen Sie
memorylimitmbniedriger als der Hostsystemspeicher und dencgroupGrenzwert (sofern vorhanden) fest, um sicherzustellen, dass genügend freier physischer Arbeitsspeicher für das Linux-Betriebssystem vorhanden ist. Wenn Sie nicht explizit festlegenmemorylimitmb, verwendet SQL Server 80 Prozent des niedrigeren Werts zwischen dem Gesamtspeicher des Systems und demcgroupGrenzwert (sofern vorhanden).Die max_server_memory Serverkonfigurationsoption beschränkt nur die Größe des SQL Server-Pufferpools und steuert nicht die allgemeine Speicherauslastung für SQL Server unter Linux. Legen Sie diesen Wert immer niedriger als
memorylimitmbfest, um sicherzustellen, dass genügend Arbeitsspeicher für die anderen Komponenten bleibt, die im vorherigen Aufzählungszeichen beschrieben sind.
Spielraum zwischen SQL Server und den Speichergrenzen des Containers
Wenn Sie SQL Server in einem Container mit einem konfigurierten Speicherlimit (z. B. der Einstellung cgroupmemory.max) ausführen, lassen Sie zwischen memory.memorylimitmb und dem Speicherlimit des Containers ausreichend Spielraum. Dieser Spielraum bietet Platz für den Overhead des Betriebssystems und Hilfsprozesse im Container.
Reservieren Sie für die meisten Bereitstellungen zwischen 10 und 20 Prozent des Containerarbeitsspeichers für das Betriebssystem und nicht von SQL Server verwendete Prozesse, und legen Sie
memory.memorylimitmbauf einen Wert unterhalb der verbleibenden Kapazität fest.Bei großen Speicherkonfigurationen kann ein prozentbasierter Puffer mehr Arbeitsspeicher reservieren als erforderlich. Beispielsweise beträgt 10 Prozent eines 256-GB-Containers etwa 25 GB, was für den Betriebssystemaufwand angemessen ist. Allerdings beträgt 10 Prozent eines 512-GB-Containers etwa 51 GB, was wahrscheinlich mehr ist als das Betriebssystem erfordert. Verwenden Sie in diesen Fällen stattdessen einen festen Puffer, ordnen Sie ihren Arbeitslast- und Betriebssystemaufwand entsprechend zu, und weisen Sie den Rest SQL Server zu.
Passen Sie den Puffer basierend auf Workloadmerkmalen, anderen Im Container ausgeführten Diensten und der Hostkonfiguration an.
Note
Kein einzelner empfohlener Kopfraumwert gilt für alle Umgebungen. Überprüfen Sie die Speichereinstellungen durch Tests, um die Systemstabilität unter Spitzenlast sicherzustellen.
Vermeiden der Konfiguration von Speicherlimits, die höher als verfügbarer Arbeitsspeicher sind
Konfigurieren Sie memory.memorylimitmb nicht auf einen höheren Wert als den verfügbaren physischen Arbeitsspeicher auf dem Host oder als die vom Container vorgegebene Speichergrenze. Wenn Sie dies tun, verbrauchen SQL Server möglicherweise aggressiven Arbeitsspeicher, sodass nicht genügend Kapazität für das Betriebssystem und unterstützende Prozesse erhalten bleibt. Diese Konfiguration kann zu folgendem Ergebnis führen:
- Erhöhter Arbeitsspeicherdruck.
- Reduzierte Systemstabilität und unerwartete Dienstunterbrechungen.
- Das Betriebssystem beendet den Prozess
sqlservraufgrund von Speichermangel (OOM).
Konfigurieren Sie SQL Server Speichergrenzen unter dem effektiven Arbeitsspeicher, der für den Host oder Container verfügbar ist, und lassen Sie ausreichend Pufferplatz für das Betriebssystem und die Laufzeitdienste.
Docker-Speicherkonfigurationsbeispiele
Die docker run --memory Option legt den cgroup Speichergrenzwert für den Container fest. Dieser Grenzwert ist die vom Kernel erzwungene harte Obergrenze für alle Prozesse im Container.
MSSQL_MEMORY_LIMIT_MB(oder memory.memorylimitmb) steuert, wie viel speicher SQL Server verwenden kann. Wie in den vorherigen Richtlinien beschrieben, legen Sie MSSQL_MEMORY_LIMIT_MB immer unter dem Speicherlimit des Containers fest, um dem Betriebssystem und zusätzlichen Prozessen ausreichend Spielraum zu lassen.
In den folgenden Beispielen wird ein Host mit 16 GB RAM verwendet. Passen Sie Werte für Ihre Umgebung an.
Nicht empfohlen: kein Speicherlimit für Container
docker run -e "ACCEPT_EULA=Y" -e "MSSQL_SA_PASSWORD=<password>" \
-e "MSSQL_MEMORY_LIMIT_MB=14336" \
-p 1433:1433 \
-d mcr.microsoft.com/mssql/server:2022-latest
Ohne --memory, hat der Behälter keine cgroup Decke.
MSSQL_MEMORY_LIMIT_MBschränkt SQL Server ein, aber andere Prozesse innerhalb des Containers können weiterhin ungebundene Hostspeicher verbrauchen.
Nicht empfohlen: Speicherlimit gleich SQL Server Arbeitsspeicherlimit
docker run -e "ACCEPT_EULA=Y" -e "MSSQL_SA_PASSWORD=<password>" \
-e "MSSQL_MEMORY_LIMIT_MB=12288" \
--memory 12g \
-p 1433:1433 \
-d mcr.microsoft.com/mssql/server:2022-latest
Beide Grenzwerte werden auf 12 GB (--memory 12g = 12.288 MB) festgelegt. Es bleibt kein Spielraum mehr für den Overhead des Betriebssystems oder für Hilfsprozesse, was zu OOM-Kills führen kann.
Nicht empfohlen: SQL Server Speichergrenzwert überschreitet den Containergrenzwert.
docker run -e "ACCEPT_EULA=Y" -e "MSSQL_SA_PASSWORD=<password>" \
-e "MSSQL_MEMORY_LIMIT_MB=14336" \
--memory 12g \
-p 1433:1433 \
-d mcr.microsoft.com/mssql/server:2022-latest
MSSQL_MEMORY_LIMIT_MB (14 GB) überschreitet den Containergrenzwert (12 GB). Dieses Szenario führt zu den OOM-Bedingungen, die unter " Vermeiden der Konfiguration von Speichergrenzwerten höher als verfügbarer Arbeitsspeicher" beschrieben werden.
Empfohlen: Container-Limit mit Puffer für das Betriebssystem
docker run -e "ACCEPT_EULA=Y" -e "MSSQL_SA_PASSWORD=<password>" \
-e "MSSQL_MEMORY_LIMIT_MB=10240" \
--memory 12g \
-p 1433:1433 \
-d mcr.microsoft.com/mssql/server:2022-latest
Der Container ist auf 12 GB (--memory 12g) beschränkt, und SQL Server ist für die Verwendung von bis zu 10 GB (MSSQL_MEMORY_LIMIT_MB=10240) konfiguriert. Die verbleibenden 2 GB (ca. 17 Prozent) lassen dem Betriebssystem und anderen Prozessen Spielraum.
Überlegungen zum Austauschen von Speicherplatz
Wenn Sie SQL Server in einem Container ausführen, aktivieren Sie swap space auf Hostebene, um das Betriebssystem und nicht SQL Server Prozesse zu schützen. Konfigurieren Sie jedoch SQL Server für den Betrieb innerhalb der konfigurierten Speichergrenzen, und verlassen Sie sich nicht auf den Austausch während des normalen Vorgangs.
Befolgen Sie die Richtlinien für speicherlimits, um sicherzustellen, dass SQL Server innerhalb des physischen Speichers oder des anwendbaren
cgroupSpeicherlimits arbeitet.Wenn Swap aktiviert ist, betrachten Sie ihn als Sicherheitsreserve für vorübergehende Speicherengpässe auf dem Host, nicht als Kapazitätsreserve für SQL Server-Workloads im Dauerbetrieb.
Important
Die Leistung von SQL Server kann sich erheblich verschlechtern, wenn Speicherknappheit Auslagerungen verursacht. Die richtige Größe des Arbeitsspeichers ist der primäre Mechanismus zum Verhindern von Speicherfehlern.