Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Denne vejledning viser dig, hvordan du træner en multivariat anomali-detektionsmodel i en Fabric-notebook ved at bruge eksempeldata gemt i et eventhouse. Derefter bruger du den trænede model i et KQL-forespørgselssæt til at score nye data og visualisere anomalier.
For baggrundsinformation, se Multivariat anomali-detektion i Microsoft Fabric - oversigt.
Forudsætninger
- Et arbejdsområde med en Microsoft Fabric-aktiveret -kapacitet.
- En admin-, bidragyder eller medlemsarbejdsområde-rolle. Du har brug for dette tilladelsesniveau for at oprette elementer som et miljø.
- Et eventhouse i dit arbejdsområde med en database.
- Eksempeldatafilen.
- Eksempelnotesbogen.
Del 1: Tænd for OneLake-tilgængelighed
Slå OneLake-tilgængelighed til, før du indlæser data i eventhouset. Denne indstilling gør de indlæste data tilgængelige i OneLake, så du senere i tutorialen kan få adgang til den samme tabel fra en notesbog.
I dit arbejdsområde åbner du eventhouse'en, som du har oprettet i forudsætningerne, og vælger derefter databasen, hvor du vil gemme dine data.
I databasens detaljepanel skal du sætte OneLake-tilgængelighed til På.

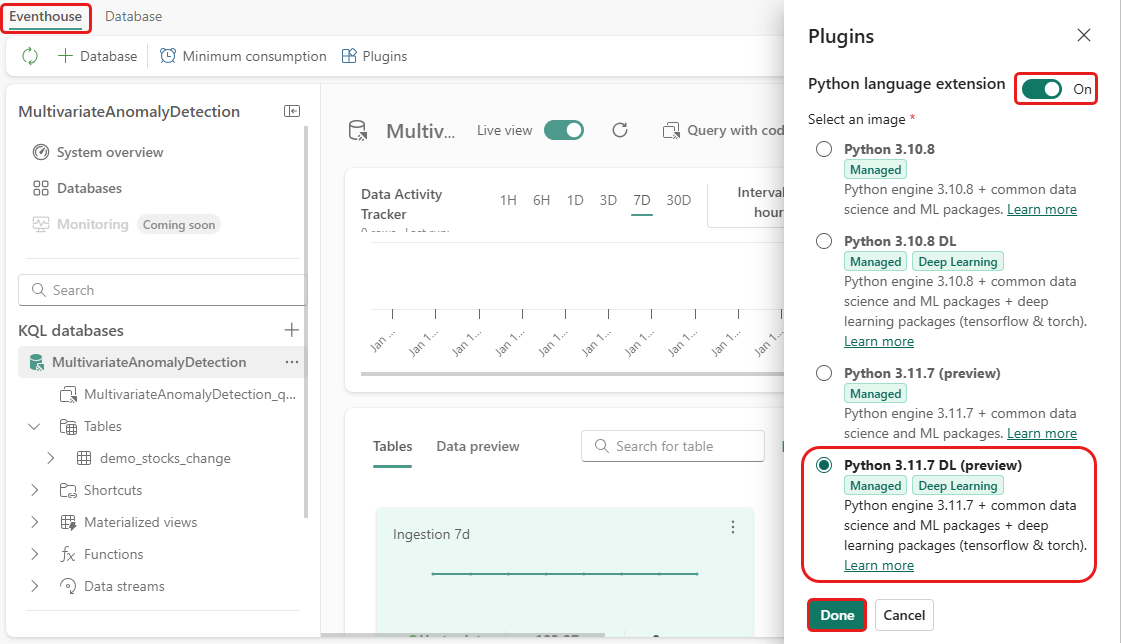
Del 2: Tænd for KQL Python-plugin'et
I dette trin tænder du for Python-plugin'et i dit eventhouse. Dette trin kræves for at køre Python-koden i KQL-forespørgselssættet i Del 9: Forudsige anomalier i et KQL-forespørgselssæt. Vælg Python-billedet, der inkluderer time-series-anomaly-detector-pakken.
I eventhouse-funktionen skal du vælge Eventhouse>Plugins på båndet.
I Plugins-panelet sætter du Python-sprogudvidelsen til På.
Vælg Python 3.11.7 DL.
Vælg Udført.

Del 3: Skab et Spark-miljø
I dette trin opretter du et Spark-miljø til at køre notebooken, som træner den multivariate anomali-detektionsmodel. For mere information, se Opret og administrer miljøer.
Fra dit arbejdsområde vælger du + Nyt element, og vælger derefter Miljø.

Indtast
MVAD_ENVfor miljønavnet, og vælg derefter Create.Under Biblioteker skal du vælge Offentlige biblioteker.
Vælg Tilføj fra PyPI.
I søgefeltet indtaster
time-series-anomaly-detectordu . I versionsboksen indtaster0.3.9du .Vælg Gem.

Vælg fanen Hjem i miljøet.
Vælg ikonet Publicer på båndet.

Vælg Publicer alle. Dette trin kan tage flere minutter at fuldføre.



Del 4: Indlæs data i eventhuset
I eventhouse, hold musen over KQL-databasen, hvor du vil gemme dine data, og vælg derefter Mere-menuen [...]>Få data>Lokal fil.

Vælg + Ny tabel, og indtast
demo_stocks_changesom tabelnavn.I upload-dialogen skal du vælge Gennemse filer, og uploade den eksempeldatafil, du har downloadet i Prerequisites.
Vælg Næste.
I afsnittet Undersøg dataene skal du kontrollere, at første række er kolonneoverskrift, er angivet til Ved.
Vælg Udfør.
Når dataene uploades, skal du vælge Luk.
Del 5: Kopier OneLake-stien
Vælg demo_stocks_change tabellen. I ruden Tabeldetaljer skal du vælge OneLake-mappe for at kopiere OneLake-stien til udklipsholderen. Gem stien i en teksteditor til senere brug.

Del 6: Forbered notesbogen
Vælg dit arbejdsområde.
Vælg Importer>notesbog>fra denne computer.
Vælg Upload, og vælg den notesbog, du har downloadet i Forudsætninger.
Når notesbogen er uploadet, kan du finde og åbne din notesbog fra dit arbejdsområde.
På det øverste bånd vælger du standardlisten for arbejdsområdet , og vælg derefter det miljø, du har oprettet i det forrige trin.

Del 7: Kør notesbogen
Importér standardpakker.
import numpy as np import pandas as pdSpark har brug for en ABFSS URI for sikkert at kunne forbinde til OneLake-lagring, så definer en hjælpefunktion, der konverterer OneLake URI til en ABFSS URI.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriErstat
OneLakeTableURImed OneLake-URI'en, som du kopierede i Del 5: Kopier OneLake-stien, og indlæsdemo_stocks_changederefter tabellen i en pandas-dataframe.onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI. abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas() df['Date'] = pd.to_datetime(df['Date']) df = df.set_index('Date').sort_index() print(df.shape) df.head(3)Kør følgende celler for at forberede trænings- og forudsigelsesdatarammerne.
Bemærk
De faktiske forudsigelser kører i eventhuset i Del 9: Forudsige anomalier i et KQL-forespørgselssæt. I et produktionsscenarie scorer man typisk nye streamingdata. I denne vejledning opdeles datasættet efter dato i trænings- og forudsigelsesintervaller for at simulere historiske og indkommende data.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.Timestamp('2023-01-01')train_df = df.loc[df.index < cutoff_date, features_cols] print(train_df.shape) train_df.head(3)train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Kør cellerne for at træne modellen og gem den i Fabric MLflow-modelregistret.
from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 params = {"sliding_window": sliding_window}model.fit(train_df, params=params)model_name = "mvad_5_stocks_model"import mlflow with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name=model_name, )Kør følgende celle for at få den registrerede modelsti, som du senere bruger til forudsigelse i KQL Python sandboxen.
from mlflow.tracking import MlflowClient client = MlflowClient() mvs = client.search_model_versions(f"name='{model_name}'") latest = max(mvs, key=lambda v: v.creation_timestamp) model_abfss = latest.source print(model_abfss)Kopier modellens URI fra outputtet fra den sidste celle. Du bruger det i Del 9.
Del 8: Opret et KQL-forespørgselssæt
Du kan få generelle oplysninger under Opret et KQL-forespørgselssæt.
- I dit arbejdsområde vælger du + Nyt element>KQL Queryset.
- Indtast
MultivariateAnomalyDetectionTutorial, og vælg derefter Create. - I OneLake-katalogvinduet skal du vælge KQL-databasen, hvor du har gemt dataene.
- Vælg Opret forbindelse.
Del 9: Forudsige anomalier i et KQL-forespørgselssæt
Kør følgende
.create-or-alter functionforespørgsel for at definere den lagredepredict_fabric_mvad_fl()funktion:.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow work_dir = os.environ.get("UPLOAD_PATH") model_dir = work_dir + '/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move(work_dir + '/MLmodel', model_dir) shutil.move(work_dir + '/conda.yaml', model_dir) shutil.move(work_dir + '/requirements.txt', model_dir) shutil.move(work_dir + '/python_env.yaml', model_dir) shutil.move(work_dir + '/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Kør følgende forudsigelsesforespørgsel. Erstat
enter your model URI heremed den URI, du kopierede i slutningen af Del 7: Kør notesbogen.Forespørgslen opdager multivariate anomalier på tværs af de fem stocks ved at bruge den trænede model og gengiver derefter resultaterne som en
anomalychart. De unormale punkter vises på den første stok (AAPL), men de repræsenterer anomalier i den fælles adfærd for alle fem stammer på en given dato.let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock price changes in % with anomalies')
Det resulterende anomalidiagram ligner følgende billede:

Fjerne ressourcer
Når du er færdig med tutorialen, slet de ressourcer, du har oprettet, for at undgå unødvendige omkostninger:
- Gå til startsiden for dit arbejdsområde.
- Slet det miljø, der er oprettet i dette selvstudium.
- Slet den notesbog, der er oprettet i dette selvstudium.
- Slet eventhouset eller databasen , der blev brugt i denne tutorial.
- Slet det KQL-forespørgselssæt, der er oprettet i dette selvstudium.